로지스틱회귀
로지스틱 회귀
- 이벤트가 발생할 확률을 결정하는데 사용되는 통계 모델
- 특성 간의 관계를 보여주고 특정 결과의 확률을 계산합니다.
사용
- 머신러닝에서 정확한 예측을 생성하는데 사용
- 선형 회귀와 유사하며 대상 변수가 이진입니다. (0,1)
측정 가능한 항목
- B, 설명 변수, 특성(측정 대상 항목)
- Y, 응답 변수, 목표 이진 변수
예시
- 학생이 시험에 합격될지 불합격될지 예측할 때
- B, 설명 변수, 특성(측정 대상 항목) : 공부한 시간
- Y, 응답 변수, 목표 이진 변수 : 합격,불합격
종류
- 이진 로지스틱 회귀 : 0,1 처럼 2가지의 결과
- 다항 로지스틱 회귀 : 응답 변수에 순서가 업는 3개 이상의 변수가 포함
- 순서 로지스틱 회귀 : 3개 이상의 변수가 포함될 수 있음, 대신 측정에는 순서가 있음, 예를 들어 1~5점으로 평가를 하는 경우
이미지
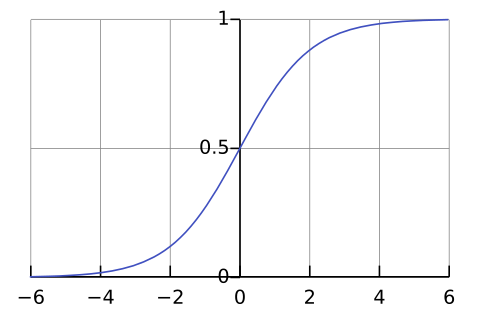
참조
예측하는 과정
로지스틱 회귀는 입력 변수와 출력 변수 간의 관계를 모델링하는 분류(Classification) 알고리즘입니다.
이 알고리즘은 입력 변수들과 출력 변수(이진 분류 문제에서는 0 또는 1) 사이의 선형 관계를 모델링하고, 그 관계를 이용해 새로운 입력 변수에 대한 출력 변수를 예측합니다.
예측하는 과정은 크게 두 가지 단계로 나눌 수 있습니다. 먼저, 학습 단계에서는 입력 변수와 출력 변수(또는 레이블)가 주어진 데이터셋을 이용해 모델을 학습합니다.
그리고 나서, 예측 단계에서는 새로운 입력 변수가 주어졌을 때, 모델을 이용해 해당 입력 변수에 대한 출력 변수를 예측합니다.
학습 단계:
로지스틱 회귀 모델은 입력 변수(X)와 출력 변수(Y) 간의 선형 관계를 모델링합니다.
이 관계는 로지스틱 함수(Logistic Function)를 사용하여 모델링됩니다.
로지스틱 함수는 S자 형태의 곡선을 그리며, 입력 변수(X)가 주어졌을 때, 출력 변수(Y)가 1이 될 확률을 예측합니다.
로지스틱 함수는 다음과 같이 정의됩니다.
p(X) = 1 / (1 + e^(-z))
여기서, z는 입력 변수(X)와 가중치(w)의 곱을 합한 값입니다. 즉, 다음과 같이 계산됩니다.
z = w_0 + w_1*X_1 + w_2*X_2 + ... + w_n*X_n
여기서, w_0은 절편(intercept)이며, w_1, w_2, …, w_n은 입력 변수(X_1, X_2, …, X_n)의 가중치(weights)입니다.
로지스틱 회귀 모델은 입력 변수와 출력 변수 간의 관계를 가장 잘 모델링할 수 있는 가중치(w)를 찾는 것이 목적입니다.
이를 위해서는 주어진 데이터셋을 이용해 로그 우도(Log-Likelihood)를 최대화 하는 가중치(w)를 찾습니다.
로그 우도는 다음과 같이 정의합니다.
L(w) = sum(y_i * log(p(x_i)) + (1 - y_i) * log(1 - p(x_i)))
여기서, y_i는 i번째 데이터 포인트의 출력 변수(레이블)입니다. p(x_i)는 i번째 데이터 포인트의 입력 변수(X_i)가 주어졌을 때, 모델이 출력 변수(Y_i)를 1로 예측할 확률을 나타냅니다.
따라서, 로그 우도는 모델이 예측한 확률이 실제 출력 변수(레이블)과 얼마나 일치하는지를 나타내며, 이를 최대화하는 가중치(w)를 찾는 것이 목적입니다.
로지스틱 회귀 모델에서 가중치(w)를 찾는 방법은 다양하지만, 대표적으로 Gradient Descent 알고리즘이 사용됩니다.
Gradient Descent 알고리즘은 로그 우도를 최대화하는 방향으로 가중치를 업데이트합니다.
이를 위해서는 로그 우도를 가중치(w)로 미분한 Gradient를 계산하고, 이 Gradient의 반대 방향으로 가중치를 업데이트합니다.
예측 단계:
로지스틱 회귀 모델은 입력 변수(X)와 가중치(w)의 곱을 합한 값(z)을 로지스틱 함수에 입력하여 출력 변수(Y)가 1이 될 확률을 예측합니다.
따라서, 예측 단계에서는 새로운 입력 변수가 주어졌을 때, 해당 입력 변수에 대한 출력 변수(레이블)을 예측하기 위해 다음과 같은 과정을 수행합니다.
입력 변수(X)에 대한 가중치(w)와 절편(intercept)을 모델에서 가져옵니다.
입력 변수(X)와 가중치(w)의 곲을 합한 값을 계산합니다. 이를 z값이라고 합니다.
z값을 로지스틱 함수에 입력하여 출력 변수(Y)가 1이 될 확률을 계산합니다.
즉, p(X) = 0.5보다 크면, 출력 변수(Y)를 1로 예측합니다. 그렇지 않으면, 출력 변수(Y)를 0으로 예측합니다.
예를 들어, 로지스틱 회귀 모델을 사용하여 스팸 메일을 분류하는 문제를 해결한다고 가정해보겠습니다.
이 경우, 입력 변수(X)는 이메일의 본문이나 제목과 같은 텍스트 데이터가 될 수 있으며, 출력 변수(Y)는 이메일의 스팸인지 아닌지를 나타내는 0 또는 1이 될 수 있습니다.
학습 단계에서는 이메일 데이터셋을 사용하여 로지스틱 회귀 모델을 학습하고, 예측 단계에서는 새로운 이메일이 주어졌을 때, 모델을 이용하여 해당 이메일이 스팸인지 아닌지 예측할 수 있습니다. 예를 들어, 새로운 이메일의 제목과 본문이 주어졌을 때, 로지스틱 회귀 모델은 다음과 같은 과정을 수행합니다.
입력 변수(X)는 이메일의 제목, 본문 같은 텍스트 데이터가 됩니다.
모델은 학습 단계에서 찾은 최적의 가중치(w)와 절편(intercept)을 사용하여, 입력 변수(X)와 가중치(w)의 곱을 합한 값을 계산합니다. 이를 z값이라고 합니다.
z값을 로지스틱 함수에 입력하여 출력 변수(Y)가 1이 될 확률을 계산합니다. 예를 들어, P(X) = 0.8이라면, 해당 이메일을 스팸으로 분류합니다.
로지스틱 회귀는 이진 분류를 위한 모델이지만, 다중 분류 문제에도 적용할 수 있습니다.
다중 분류 문제에서는, 로지스틱 회귀 모델을 각 클래스(카테고리)에 대해 독립적으로 학습합니다.
예를 들어, 손글씨 숫자 이미지를 분류하는 문제에서는, 로지스틱 회귀 모델을 0부터 9까지의 각 숫자에 대해 학습합니다.
이 경우, 각 로지스틱 회귀 모델은 해당 숫자에 대해 에측된 확률을 출력하며, 확률이 가장 높은 숫자가 해당 이미지의 분류 결과가 됩니다.
로지스틱 회귀는 간단하고 효율적인 모델이며, 다양한 분야에서 사용됩니다.
예를 들어, 의학 분야에서는 질병 예측 모델에 사용되고, 마케팅 분야에서는 고객 세분화 모델에 사용됩니다.